Methodology
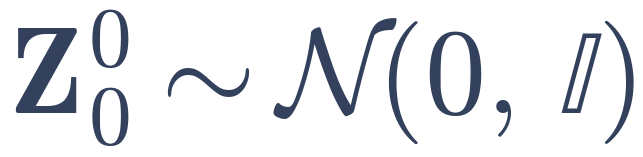
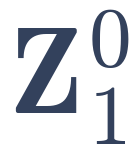
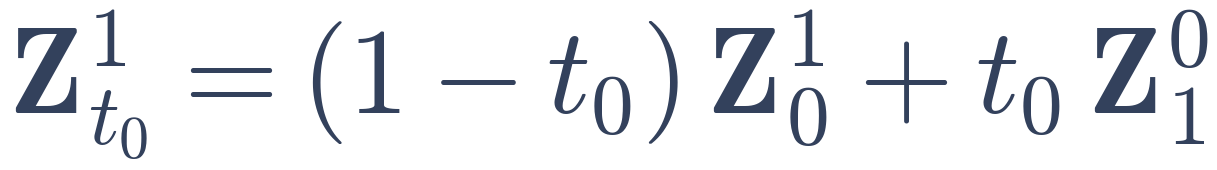

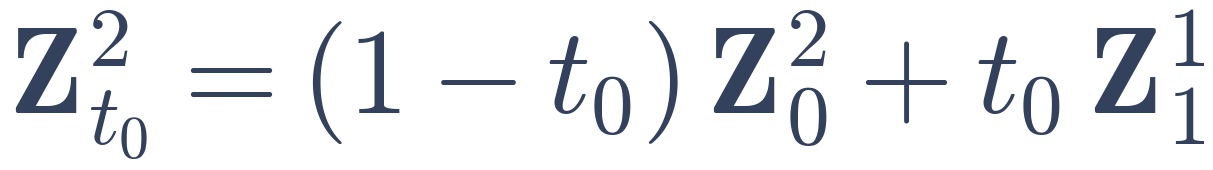


















 −
− )
)

From a monocular input video, an image-to-3D DiT produces a temporally consistent per-frame 3D reconstruction through causal latent propagation, where each frame’s 3D latent is initialized by mixing fresh noise with the previous denoised latent, and the outputs are decoded into independent sets of Gaussian splats. We consolidate these per-frame predicted sets into a single 4D complete Gaussian Splat reconstruction, represented by canonical Gaussians animated by two sets of sparse deformation nodes. The first set is fit to the per-frame outputs through a reconstruction loss (ℒrec) on the per-frame reconstructed geometry, and the appearance is then refined by optimizing the color as well as a second set of fine appearance deformation nodes against occlusion-inpainted frames and rendering loss: the 4D reconstruction is rendered from random novel views and noised, and a novel-view diffusion prior denoises them, conditioned on the per-frame frames that have their occlusions inpainted using the per-frame 3D outputs. The resulting denoised novel-view sample distillation together with a rendering loss on the visible pixels supply an appearance supervision signal (ℒapp) that aggregates visible details across frames and hallucinates in occluded and unobserved regions.